Iris 資料集是機器學習中的經典範例,包含 150 筆樣本,每筆樣本有 4 個特徵,並且有 3 種不同的花卉分類。今天我們將深入講解這個資料集的內容,並將其輸出成 CSV 檔案。
首先,在 Google 雲端硬碟中建立一個叫做 Iris 的資料夾。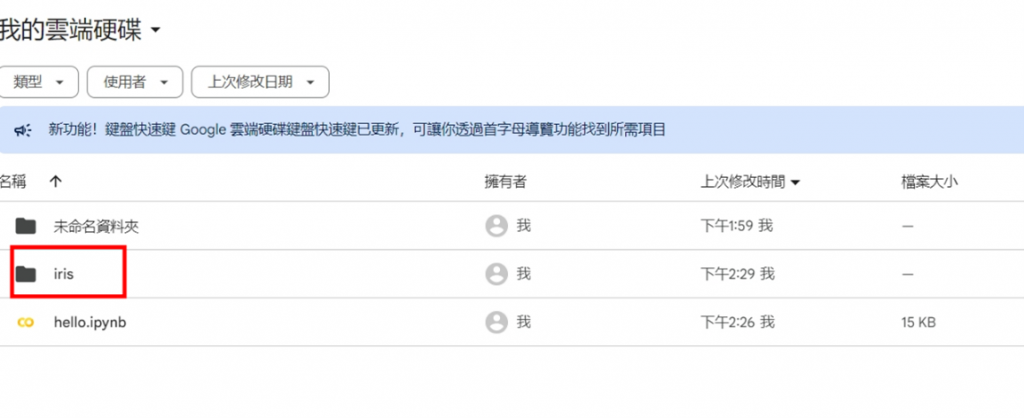
接著,在資料夾中開啟一個 Google Colab 筆記本,並將其命名為 Iris_output。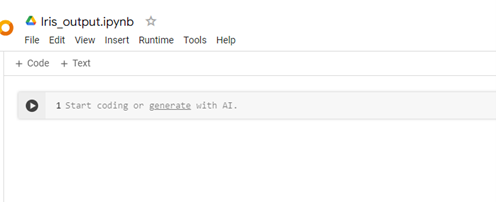
第一段程式碼先寫入:
from google.colab import drive
drive.mount('/content/drive')
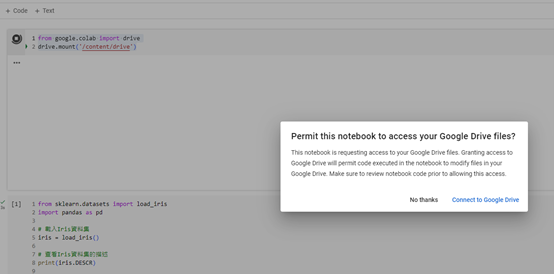
執行後點選 Connect,並點選全部打勾進行授權。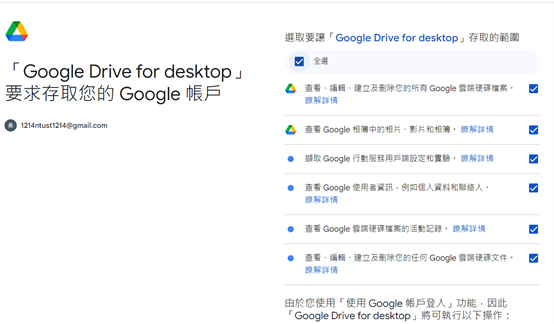
我們來載入 Iris 資料集,並檢視其結構:
from sklearn.datasets import load_iris
import pandas as pd
# 載入 Iris 資料集
iris = load_iris()
# 查看 Iris 資料集的描述
print(iris.DESCR)
這段程式碼會輸出 Iris 資料集的描述,包括資料集的背景資訊和各個特徵的簡介。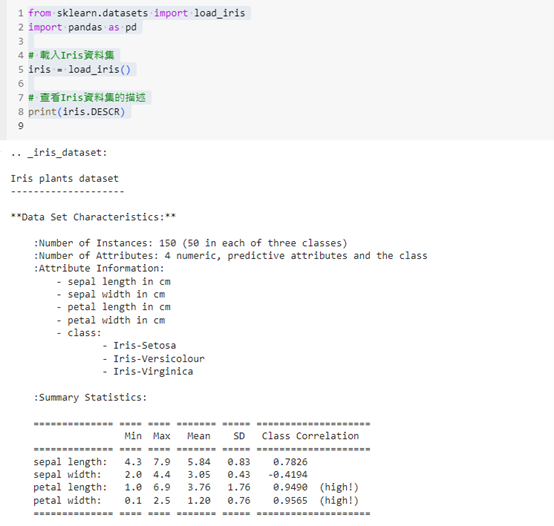
Iris 資料集的每筆資料有 4 個特徵,分別是:
每筆資料都會根據這 4 個特徵進行測量,最終目的是預測花卉的種類。總共有 3 種花卉類別(target),分別是:
為了更方便地檢視和操作資料,我們將 Iris 資料集轉換為 Pandas DataFrame 格式:
# 將資料轉換為 DataFrame
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 加入 target 欄位
iris_df['target'] = iris.target
# 查看前幾筆資料
print(iris_df.head())
這樣,我們就可以清楚地看到每筆資料的特徵值及其對應的花卉類別。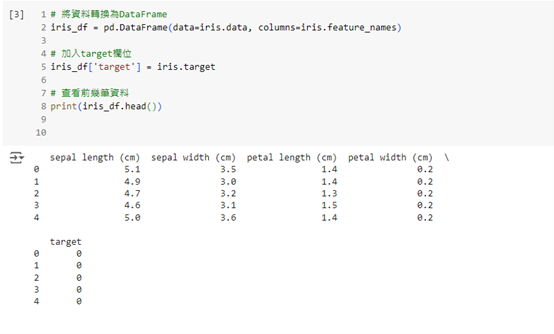
最後,我們將處理好的 Iris 資料集儲存為 CSV 檔案,方便後續的操作和分析:
# 將 CSV 檔案移動到 Google Drive
iris_df.to_csv('/content/drive/My Drive/Iris/iris_dataset.csv', index=False)
print("Iris 資料集已成功輸出成 CSV 檔案。")
這樣,你就可以在自己的資料夾中找到 iris_dataset.csv,並使用 Excel 或其他工具進行查看。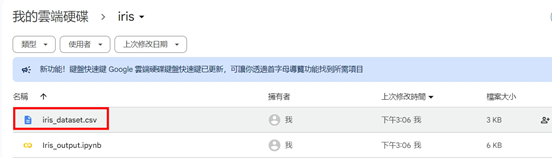
今天我們介紹了 Iris 資料集的特徵,並進行了基本的資料處理。透過這個過程,我們可以更深入地理解資料集中的數據,並為後續的資料分析與機器學習模型建構打下基礎。


 iThome鐵人賽
iThome鐵人賽